When a major incident hits, the first instinct is to look for the broken server, failed deploy, or overloaded database.
But after decades in DevOps, SRE, and platform enablement, I’ve learned something far more consistent:
Major incidents rarely fail because of technology.
They fail because the systems around the technology collapse.
Over and over, I see the same four breakdowns:
- Documentation
- Alerting
- Communication
- Ownership & escalation
Modern stacks are sophisticated.
Modern organizations… less so.
Let’s walk through what actually fails — and how AI-native platforms finally give us a path forward.
1. Documentation Failure: Tribal Knowledge Is Not a Strategy
What fails
- Runbooks are outdated or missing
- Architecture diagrams don’t match reality
- Service ownership lives in someone’s head
- New responders don’t know where to start
During incidents, teams burn time answering basic questions:
- What services are involved?
- Who owns them?
- What changed?
That’s not troubleshooting. That’s archaeology.
How to fix it
Documentation must become living operational context:
- Service ownership per component
- Minimal runbooks focused on failure modes
- Dependency maps generated from telemetry
- “Day-2 docs” (how things break, not just how they’re built)
If it isn’t exercised regularly, it isn’t documentation — it’s decoration.
2. Alerting Failure: Too Late or Too Loud
Most organizations suffer from one of two extremes:
- Alert floods with no signal
- Silence until customers complain
Typical mistakes:
- Infrastructure thresholds instead of user impact
- Hundreds of uncorrelated alerts
- No understanding of blast radius
Alert fatigue slows response. Slow response extends outages.
The shift that matters
Move from component health to experience health:
- Synthetic user journeys
- SLO / error-budget based alerting
- Correlated logs, metrics, and traces
- Root-cause grouping instead of raw events
Instead of:
CPU is high
You want:
Checkout latency is degrading for 42% of users — payment service is primary contributor.
That’s actionable.
3. Communication Failure: Everyone Working, Nobody Leading
You’ve seen this:
- Multiple Slack threads
- Duplicate investigations
- Stakeholders interrupting engineers
- No single source of truth
Engineers context-switch instead of fixing.
Fix: Incident command, every time
Establish clear roles:
- Incident Commander – owns coordination
- Technical Lead – drives diagnosis
- Comms Lead – handles stakeholders
- Scribe – captures timeline
Create:
- One incident channel
- One status doc
- Regular update cadence
Engineering fixes systems.
Process protects engineers.
4. Ownership & Escalation Failure: The Silent Killer
This one is brutal:
- “I thought your team owned that.”
- Senior engineers pulled in too late
- Vendors engaged after hours of spinning
Meanwhile the clock keeps running.
Fix it before the outage
Predefine:
- Service ownership (single accountable team)
- Escalation paths with time thresholds
- Vendor engagement criteria
Example:
- 15 min unresolved → platform lead
- 30 min → director
- 45 min → vendor bridge
No debate. Just execution.
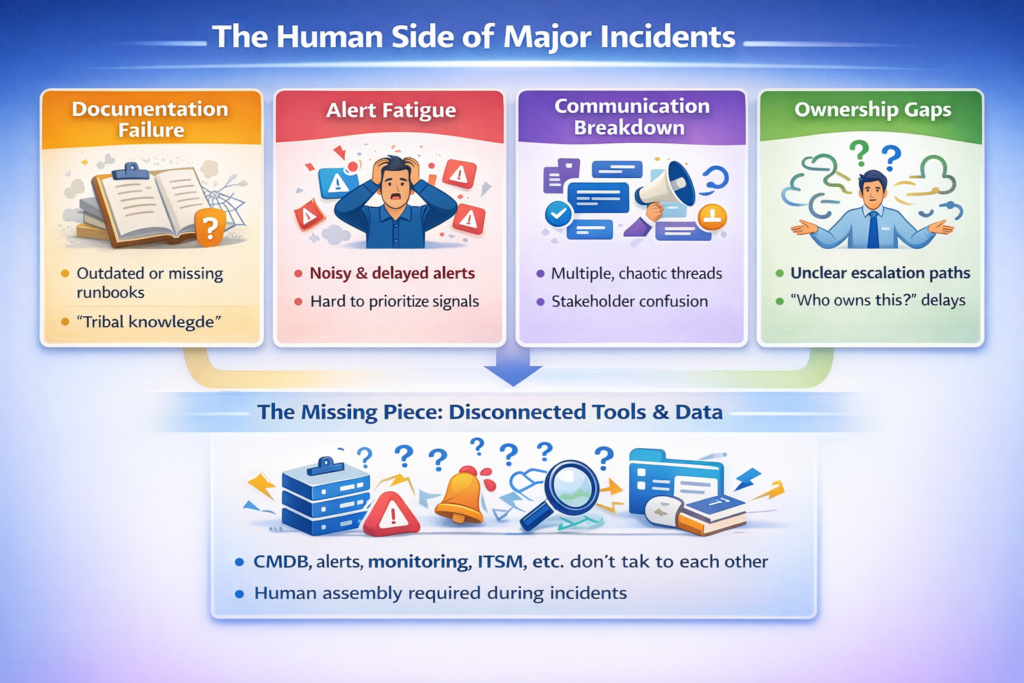
The Missing Piece: Connected Operational Context
Here’s the deeper problem:
Most enterprises already have the tools.
They just don’t talk to each other.
You’ll see:
- CMDB knows what exists
- Observability knows what’s slow
- Alerting knows what’s broken
- ITSM knows who’s on call
…but nobody knows everything.
So humans manually stitch together dashboards, tickets, runbooks, ownership, and architecture while production is burning.
That cognitive load is what kills MTTR.
Some organizations are starting to close this gap — for example, ServiceNow consuming telemetry from Dynatrace to enrich incidents with real operational data. This creates a more holistic view: services, dependencies, alerts, and ownership finally converge.
That’s the foundation.
AI and MCP-style integrations simply take this to the next level.