Category: DevOps
-

Aligning Engineering With the Business
Why DevOps and SRE Are Not Cost Centers — They Are Revenue Protectors In most organizations, product teams are tightly aligned with the business. They: That alignment makes sense. New features generate growth. But here’s the quiet tension in many companies: While product is rewarded for shipping fast, DevOps and SRE are responsible for keeping…
-

Your Mac Mini AI Lab Is Awesome. It’s Also Going to Be Obsolete.
When I built my Mac Mini AI lab, it felt like 1995 again. Local models. Ollama. VMs in Parallels. OpenClaw agents. Telegram bots. New Relic instrumentation feeding telemetry into reasoning loops. It was fun. It was technical. It scratched that engineer itch that says: “I want to understand what’s happening under the hood.” And I…
-
When “99.9% Uptime” Still Costs Millions
The Hidden Financial Risk Inside Most SLAs In enterprise environments, SLAs aren’t technical documents. They are financial instruments. I’ve worked with large strategic partners who required specific uptime guarantees — 99.9%, 99.95%, sometimes higher. If we missed those targets, there were monetary penalties. Credits. Escalations. Executive conversations. Why? Because downtime wasn’t just a technical issue.…
-

SLO Math for Humans
The actual calculations, the conversations with leadership, and why your first SLO will probably be wrong Most SRE guides explain Service Level Objectives like this: “An SLO is a target value or range for a service level that’s measured by an SLI.” That definition is correct. It’s also useless. What people actually need to know:…
-
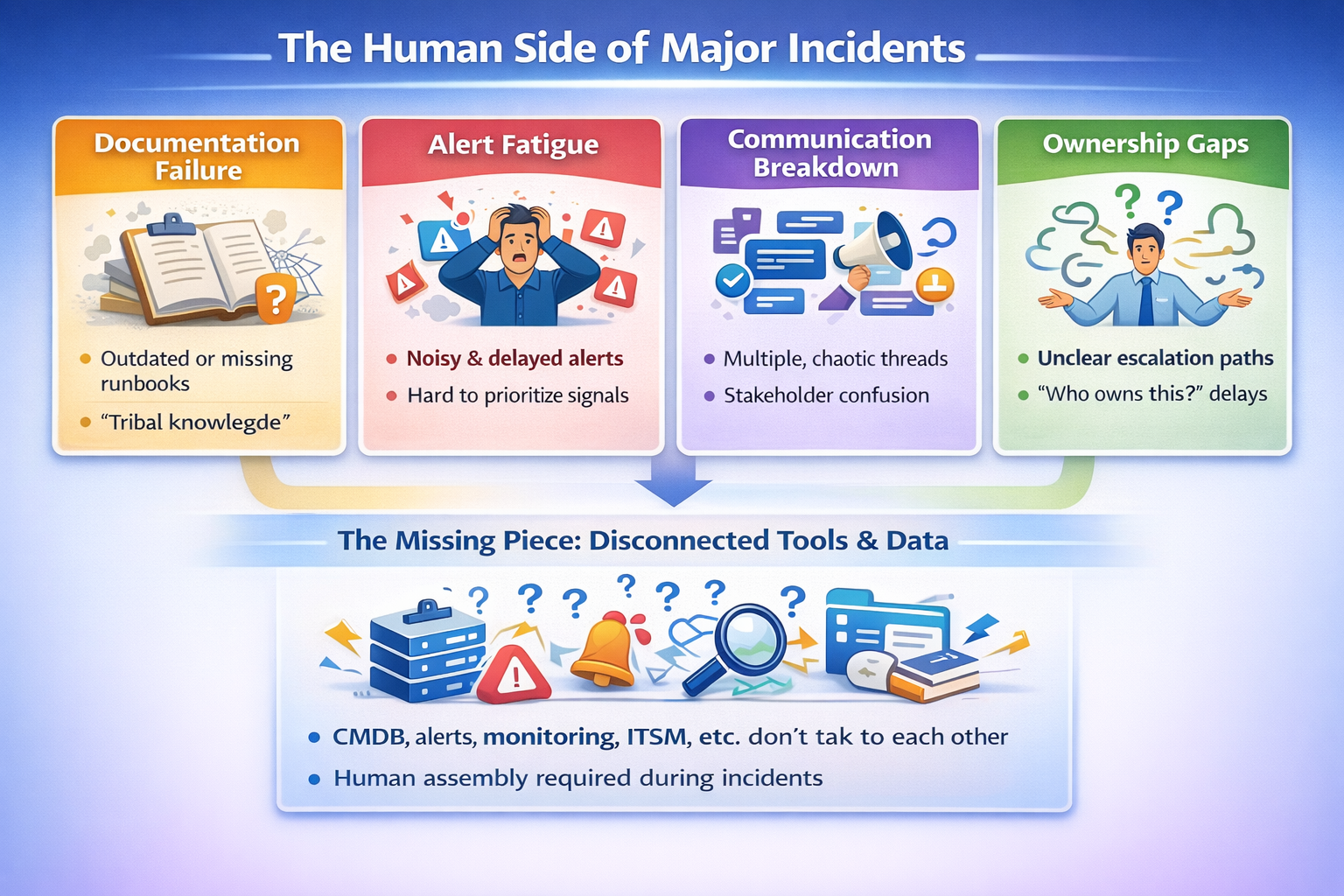
Major Incidents Aren’t Technical Failures — They’re Systems Failures
When a major incident hits, the first instinct is to look for the broken server, failed deploy, or overloaded database. But after decades in DevOps, SRE, and platform enablement, I’ve learned something far more consistent: Major incidents rarely fail because of technology. They fail because the systems around the technology collapse. Over and over, I…
-
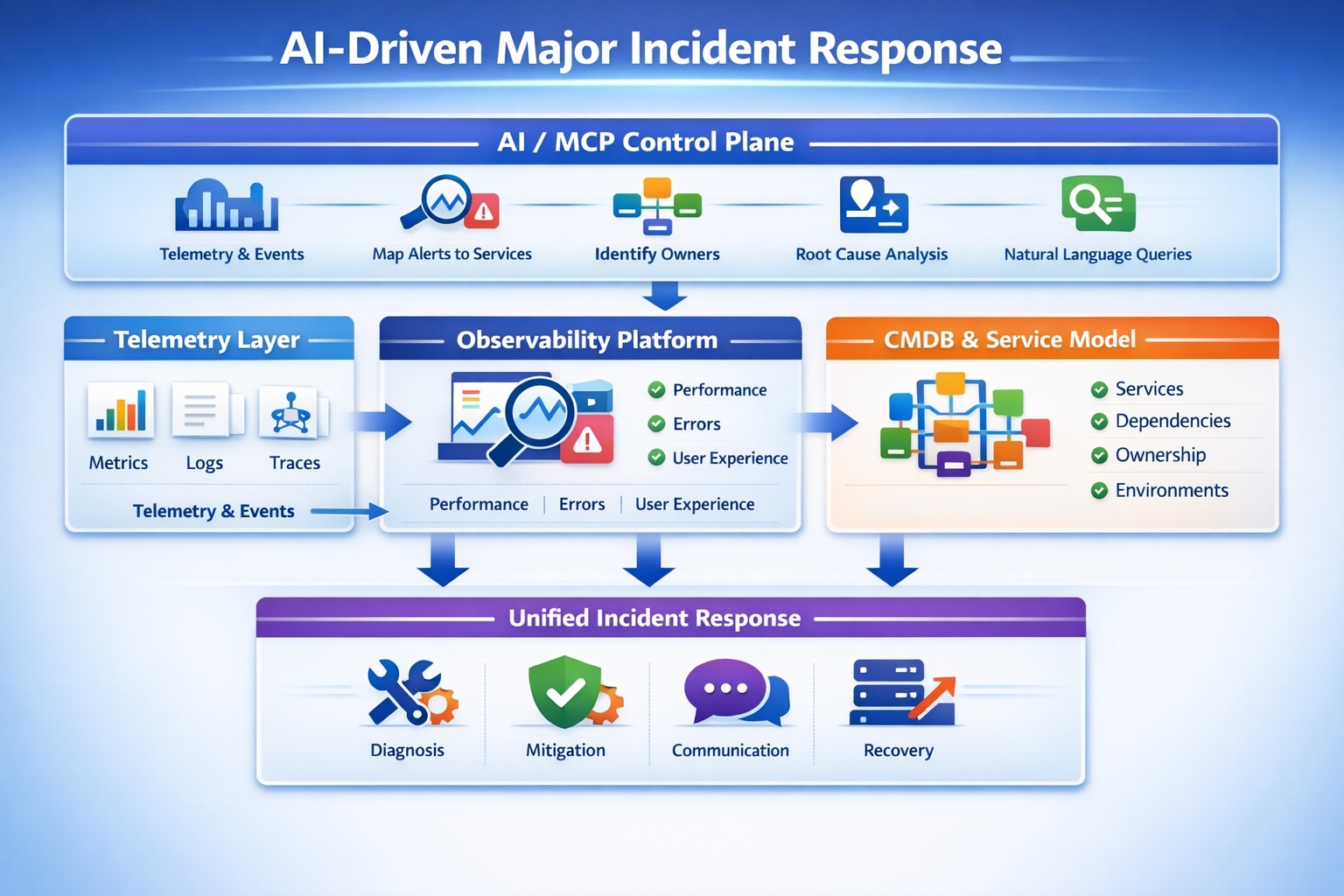
From Chaos to Context: AI-Driven Major Incident Response
In Part 1, we covered what actually fails during major incidents: That’s the baseline reality in most enterprises today. This article is about what comes next. Not “AI for dashboards.” Not chatbots bolted onto ticketing systems. I’m talking about AI as the operational control plane — where observability, CMDB, ITSM, and ownership models finally converge…
-
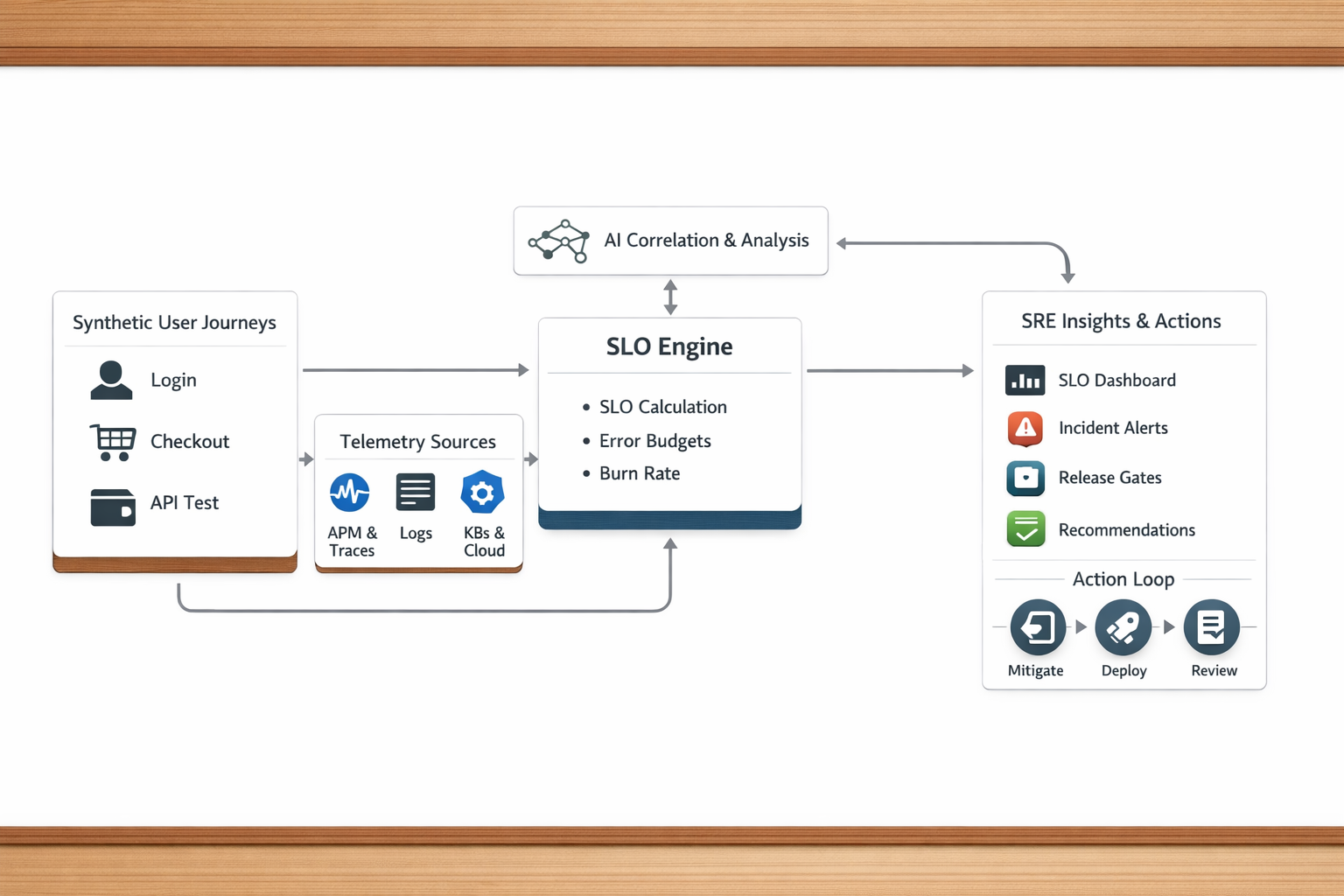
Next-Level SRE: Experience-First Reliability with AI-Driven SLO Attribution
Most organizations can show you dashboards. Far fewer can show you a live, continuously computed SLO for a critical user journey — and even fewer can tell you what’s burning that SLO right now and why. That’s the difference between traditional monitoring and next-level SRE. Next-level SRE isn’t more charts. It’s a closed-loop system: Reliability…
-

AI in Software Engineering: Speed, Scale, and the New Productivity Frontier
Artificial intelligence isn’t just a buzzword — it’s materially transforming how software gets built. In 2025–26, AI-powered coding tools have moved from niche experiment to core engineering workflow, reshaping everything from individual productivity to platform enablement across DevOps, DataOps, and delivery pipelines. Recent data shows this shift isn’t hype — it’s reality: These figures confirm…
-
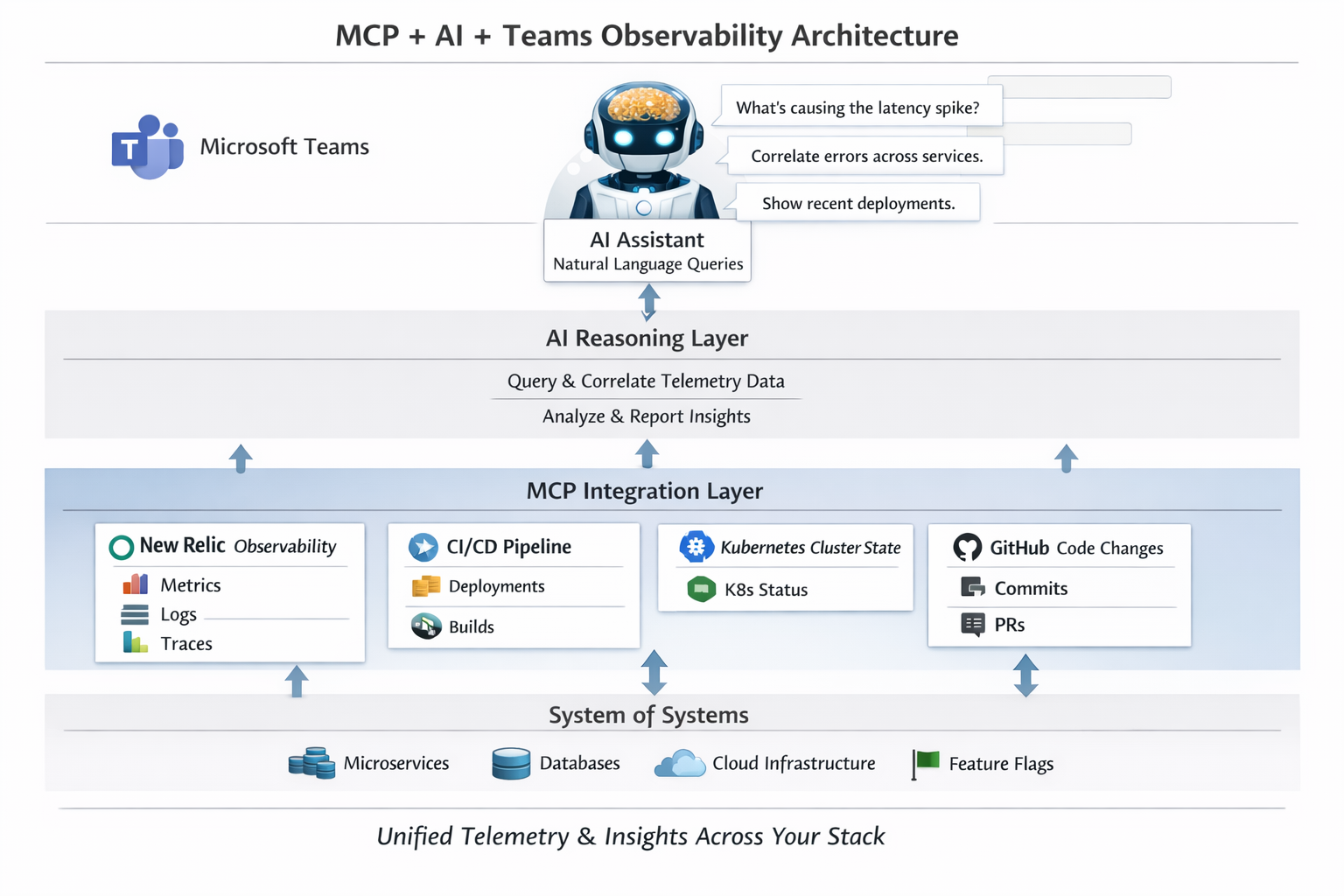
AI-Driven Observability with MCP: Query Your Entire System When Things Go Wrong
Modern distributed systems don’t fail loudly — they fail subtly. A small latency increase in one service cascades into customer impact three layers away. A misconfigured feature flag quietly degrades performance. A database connection pool exhausts itself under load. By the time humans notice, the system is already burning. This is exactly where Model Context…
-

Transforming Delivery Teams with DevOps: From Process to Purpose
Discover how to transform your delivery teams into agile enablement groups using DevOps practices for better efficiency and collaboration.