In Part 1, we covered what actually fails during major incidents:
- Documentation collapses into tribal knowledge
- Alerting becomes noise instead of signal
- Communication fragments across tools
- Ownership and escalation stall recovery
- And everything depends on humans manually stitching context together
That’s the baseline reality in most enterprises today.
This article is about what comes next.
Not “AI for dashboards.”
Not chatbots bolted onto ticketing systems.
I’m talking about AI as the operational control plane — where observability, CMDB, ITSM, and ownership models finally converge into a single, reasoning system.
The Core Shift: From Tools to Systems
Most organizations already have:
- Monitoring
- APM
- CMDB
- Incident management
- Chat platforms
- Runbooks
But these exist as disconnected products.
During incidents, engineers become the integration layer.
They:
- correlate alerts
- hunt dashboards
- search runbooks
- page owners
- explain status to leadership
That cognitive overhead is what stretches MTTR.
AI-driven response flips this model.
Instead of engineers assembling context…
…the platform presents it.
What “AI-Driven” Actually Means (Practically)
Let’s get concrete.
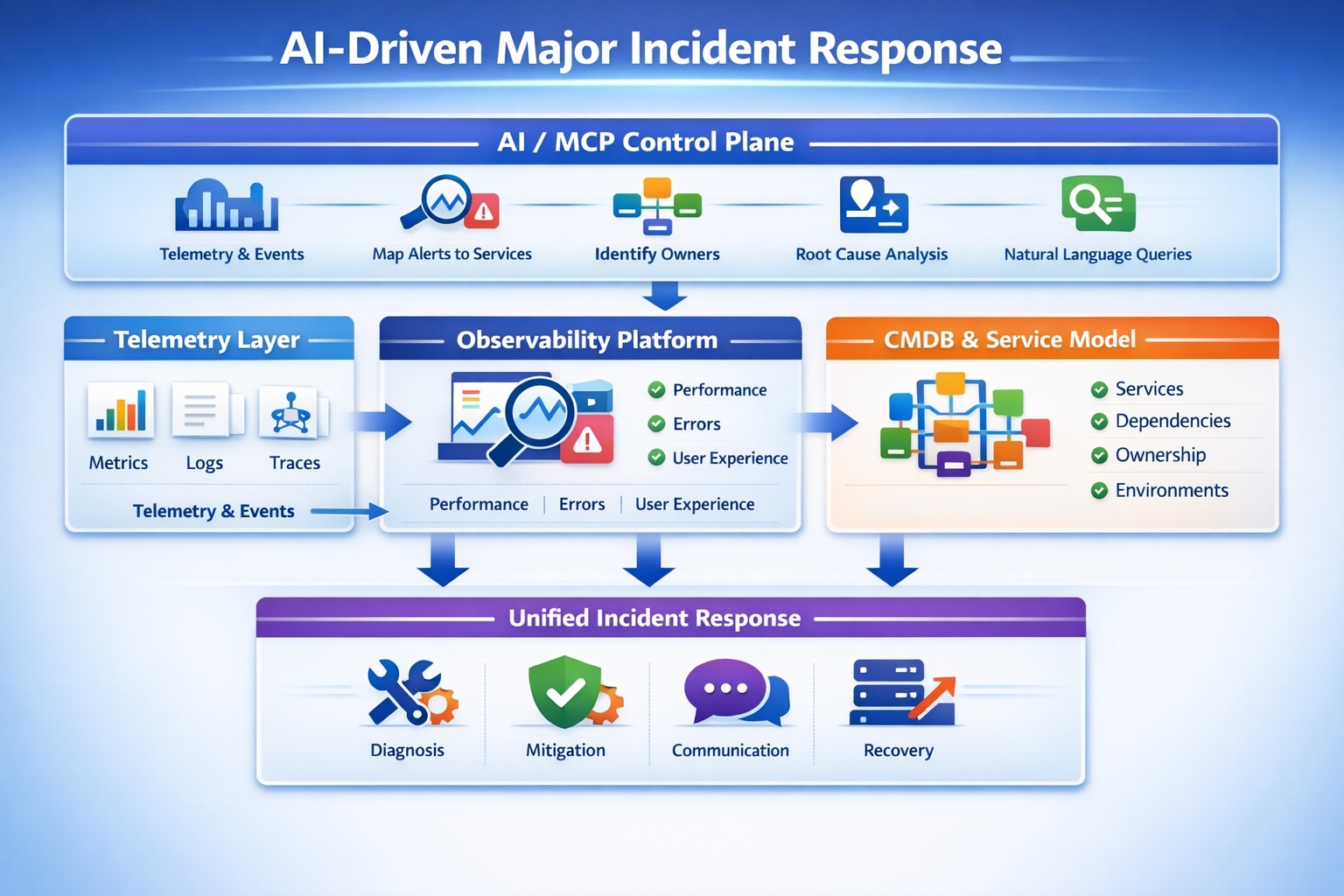
An AI-native incident platform does five things exceptionally well:
1. Correlates Telemetry Automatically
Metrics, logs, traces, synthetics — all grouped into a single incident narrative.
Instead of 200 alerts, you get:
Checkout latency degradation tied to payment-service dependency after deployment XYZ.
Signal replaces noise.
2. Maps Alerts to Services (Not Hosts)
This is critical.
Alerts attach directly to:
- logical services
- upstream dependencies
- environments
- owning teams
This is where CMDB finally becomes operational instead of administrative.
Some enterprises are already moving here — for example, ServiceNow consuming real-time signals from platforms like Dynatrace to enrich incidents with topology, ownership, and performance context.
That integration alone eliminates huge amounts of guesswork.
3. Identifies Ownership Instantly
No more:
“Who owns this?”
The system already knows:
- service owner
- escalation chain
- on-call engineer
- business stakeholder
Paging becomes deterministic.
Not emotional.
4. Accelerates Root Cause with AI Reasoning
Instead of engineers scanning dashboards:
AI evaluates:
- recent changes
- dependency anomalies
- historical incident patterns
- correlated signals
It doesn’t replace human judgment — it narrows the search space.
You start 80% closer to root cause.
5. Enables Plain-English System Queries
This is where MCP-style integrations shine.
You can ask:
Why are checkout failures increasing in production?
And get back:
- impacted service
- upstream dependency
- recent deployment
- owning team
- suggested mitigation
That’s not magic.
That’s connected data + reasoning.

Why You Don’t Need Full Autonomy on Day One
Here’s the important part:
You don’t need agentic AI running production to see massive gains.
Simply achieving:
- alerts mapped to services
- services mapped to owners
- owners mapped to escalation
- telemetry mapped to user impact
already removes:
- tribal knowledge
- Slack archaeology
- ownership confusion
- manual correlation
That alone can cut incident duration dramatically.
AI just accelerates what good platform engineering should already be doing.
The Deeper Truth
Major incidents last longer than they should because:
- context lives in humans
- ownership lives in spreadsheets
- dependencies live in diagrams
- telemetry lives in dashboards
AI-native platforms centralize that knowledge.
So instead of engineers searching for truth…
…the system presents it.
Or more bluntly:
AI doesn’t replace SREs.
It removes the scavenger hunt.
Closing Thought
We don’t need smarter engineers during incidents.
We need smarter systems before incidents.
Reliability isn’t built when production is on fire.
It’s built quietly — through connected telemetry, clear ownership, automated correlation, and platforms that understand the systems they operate.
That’s what AI-driven incident response really means.
Not automation for automation’s sake.
Operational coherence.