Most organizations can show you dashboards.
Far fewer can show you a live, continuously computed SLO for a critical user journey — and even fewer can tell you what’s burning that SLO right now and why.
That’s the difference between traditional monitoring and next-level SRE.
Next-level SRE isn’t more charts.
It’s a closed-loop system:
- Measure real user experience
- Compute SLOs continuously
- Correlate signals across the stack
- Attribute impact to root causes
- Feed that truth back into incident response and release decisions
Reliability becomes something you operate, not something you review once a month.
Infrastructure Signals vs Experience Signals
Most teams start their SRE journey by measuring what infrastructure exposes by default:
- CPU utilization
- Memory pressure
- Pod restarts
- Node availability
These are familiar. They’re easy. They’re technically meaningful.
But they’re also internal signals.
Users don’t experience CPU.
They experience:
- Failed logins
- Slow page loads
- Broken checkout flows
- APIs that time out mid-transaction
This is where many SRE programs stall.
Teams optimize machines while customers suffer.
True SRE maturity starts at the user boundary.
Why Synthetics Should Define Your Primary SLIs
This is why I anchor reliability around synthetic user journeys using New Relic Synthetics.
Synthetics gives you something most telemetry can’t:
A consistent, external, experience-first truth.
Instead of asking:
“Is infrastructure healthy?”
You ask:
“Can a customer complete the workflow right now — from multiple regions?”
That distinction matters.
In practice, my loop looks like this:
- Synthetics define the SLI (login works, checkout completes, API responds under threshold)
- SLOs are computed directly from those journeys
- APM, logs, and infrastructure explain deviations
- AI correlates signals across the stack
- Humans decide what to fix and what to trade off
Experience first. Telemetry second.
CPU becomes a diagnostic signal.
User experience becomes the reliability signal.
Continuous SLOs: Turning Experience into Operational Truth
Once you have experience-based SLIs, SLO math becomes straightforward:
- Availability SLO = successful journeys / total journeys
- Latency SLO = % of journeys under threshold
- Error budget = allowed failures over time
- Burn rate = how fast you’re consuming that budget
The key shift is continuous computation.
Not weekly reports.
Not monthly reviews.
Live SLO health.
Live burn rate.
Live attribution.
Your SLOs should behave like financial metrics — always current, always actionable.
The Next Level: Attribution Across the Entire Stack
Knowing that an SLO is burning is useful.
Knowing why is transformational.
This is where SRE moves beyond observability into systems thinking.
Modern environments generate signals everywhere:
- Synthetic journeys
- Distributed traces
- Application metrics
- Logs
- Kubernetes and cloud telemetry
- CI/CD events
- Incident timelines
Individually, they tell partial stories.
Together, they form a graph.
Next-level SRE treats reliability as a relationship problem, not a dashboard problem:
- Which dependency contributes most to current latency?
- Did this degradation start after a deployment?
- Is one region driving 80% of failures?
- Are retries masking deeper correctness issues?
Instead of flooding engineers with alerts, the system answers:
“95% of current SLO burn is caused by downstream timeout spikes in us-east-1, starting 11 minutes after release r2026.02.03-17.”
That’s actionable.
Where AI Helps (and Where It Doesn’t)
AI becomes incredibly powerful once you start from experience-based SLIs.
Used correctly, it can:
- Surface candidate SLIs by clustering real and synthetic user paths
- Detect leading indicators that precede SLO burn
- Correlate degradation with deploys, infrastructure changes, or dependencies
- Highlight which signals matter most during incidents
AI excels at:
- Pattern discovery
- Correlation
- Attribution
- Prioritization
But here’s the critical point:
AI cannot decide what reliability means for your product.
That’s still a human responsibility.
Left on its own, AI optimizes what’s measurable — not what’s meaningful.
It will happily recommend CPU, heap size, or request counts because they’re statistically clean.
But those don’t define customer trust.
Choosing SLIs is a product decision disguised as a technical one.
You’re answering:
- What workflows define success?
- What failures cause real user pain?
- What signals warn us before customers notice?
- What degradation are we willing to tolerate?
AI accelerates discovery.
Humans set intent.
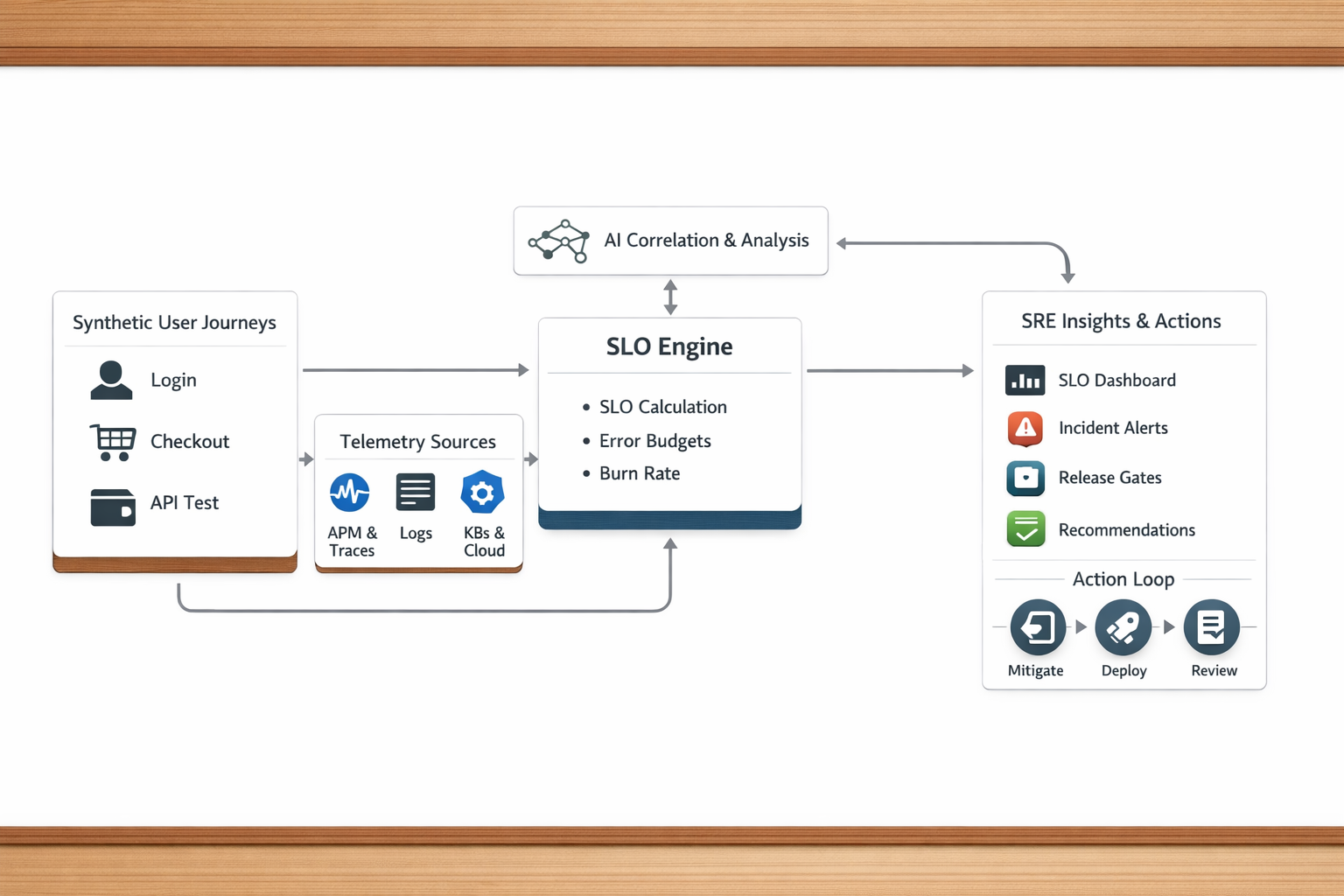
The Architecture: Experience → SLO Engine → AI Attribution
Here’s the reference architecture that ties it all together:

Flow:
1. Synthetic User Journeys
Login, checkout, API workflows run continuously from multiple regions.
These define your primary SLIs.
2. Telemetry Sources
APM, logs, traces, Kubernetes, cloud metrics, CI/CD events.
These explain why experience changes.
3. SLO Engine
Consumes SLIs and computes:
- SLO compliance
- Error budgets
- Burn rates
Continuously.
4. AI Correlation Layer
Connects signals across domains:
- Experience → service → dependency → infrastructure → release
Produces ranked attribution and leading indicators.
5. SRE Interface (Chat / Dashboards / Incidents)
Engineers ask questions in natural language:
- Why is checkout slow?
- What’s burning our error budget?
- Did the last deploy cause this?
They receive contextual answers, not raw metrics.
6. Action Loop
Results feed:
- Incident response
- Release gates
- Error budget policy
- Postmortems
- Engineering priorities
Reliability becomes a living feedback system.
Final Thought
Next-level SRE isn’t about watching systems.
It’s about understanding experience, computing reliability continuously, and using AI to surface truth — so humans can make better decisions.
CPU is a diagnostic signal.
User experience is the reliability signal.
That’s the shift.